
GraphQL subscriptions are the key part of our environment because it allows using the same schema/query based concept but with live WebSocket updates over multiple UI components. Especially considering our use-case for UI <> API communication at Hexometer.com, some of our website analysis tools can give a response with a partial data or it could take a significant amount of time. Using WebSockets allows us to send data to UI whenever our tools are ready to respond.
Besides UI convenience, there is actually a lot of benefits in having Queue + PubSub based system to handle user requests, because everything operates in an async way, without spinning up new service or allocating more resources to process every request. However, of course, there are some downsides, specifically managing WebSocket connections could require a lot more resources than a standard request-response cycle.
Our Base Setup
All requests to our infrastructure are passing through our Nginx instance, which then makes a proxy to a specific service based on request. The same happens with our Node.js API instance, which handles GraphQL Websocket subscriptions over our Apollo Server.
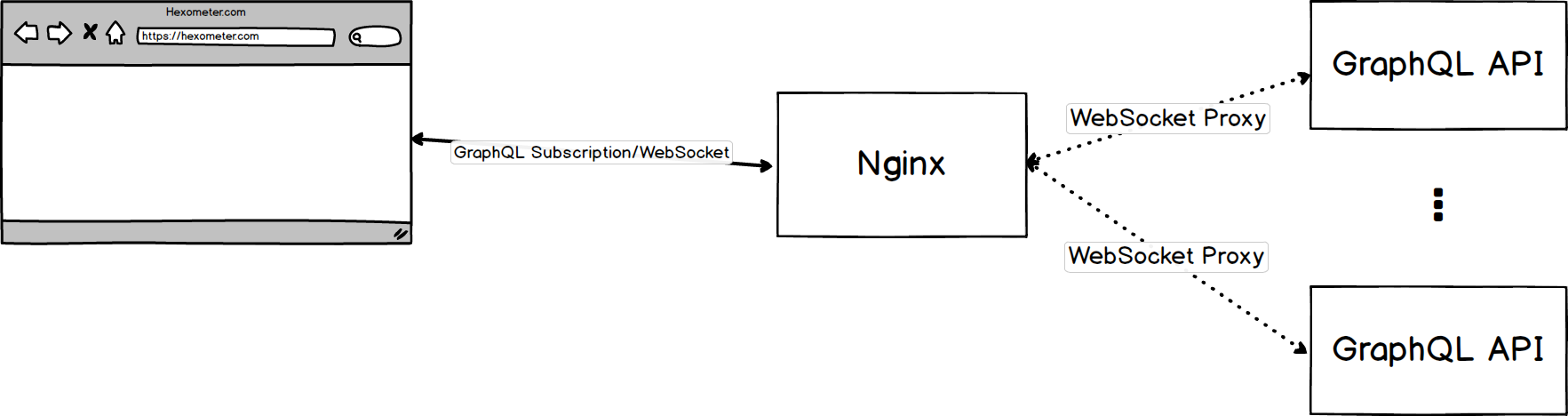
Based on this structure and our benchmarks, each WebSocket connection on average takes about 4Kb memory, which is not a big deal, but if you calculate how many live connections and active website analysis we are doing, keeping live WebSockets connections gets more and more expensive.
The main problem with WebSockets is that resource usage grows exponentially, and it is very hard to predict how to match it will grow over time. Sometimes Node.js isn’t freeing up memory when a connection is closed because there is a specific timeout option by default.
Apollo Server setup
Generally, we don’t have any custom stuff here, it is a basic Apollo Server with some middleware to handle connection, validate or pass authentication process over it. We use cors module to be able to keep our API endpoint as a subdomain and access it from multiple UI projects.
const server = new ApolloServer({
resolvers: Resolvers,
typeDefs,
context: async ({ req }) => {
// Authentication and Connection validation goes here
},
subscriptions: {
keepAlive: 1000,
onConnect: async (
connectionParams: ConnectionParamsObject,
websocket,
context
) => {
// Handling connection context here
},
onDisconnect: (websocket, context) => {
// console.log("WS Disconnected! -> ", JSON.stringify(context));
},
path: '/api/ws'
}
});
const app = express();
app.use(cors());
server.applyMiddleware({ app, path: '/api/ql', cors: false });
const httpServer = http.createServer(app);
server.installSubscriptionHandlers(httpServer);
const port = process.env.HEXOMETER_PORT || 4000;
httpServer.listen({ port }, () => {
console.log(
`🚀 Server ready at [http://localhost:${port}${server.graphqlPath}`](http://localhost:${port}${server.graphqlPath}`)
);
console.log(
`🚀 Subscriptions ready at ws://localhost:${port}${
server.subscriptionsPath
}`
);
});
As you may notice we use an express to make a basic routing and connect over Apollo Server, but, it is just for having some routing if we will need an external REST Endpoint (just in case). Otherwise, we are using only GraphQL based queries, mutations and subscriptions across all our apps. Even if we need to make a request from other services to our main API we are making a basic HTTP Request with a GraphQL query body, it’s just that simple to follow the rules :)
GraphQL Subscriptions
The main concept behind GraphQL subscriptions is to send a specific type based subscription request, and keep infinite async iterator alive, which allows sending back to UI messages whenever we need from our API endpoint. For making all that process we are using our custom-built PubSub library very similar to what Apollo Server is giving by default.
import { PubSub } from 'apollo-server-express';
....
export const pubsub = new PubSub();
....
async subscribeResolver(parent: Object, args: Object, context: GrqphqlContext) {
return pubsub.asyncIterator(topic);
}
....
// After some specific events, we can publish to that asyncIterator
// Which will send Websocket message to UI and will try to get another async iterator message
pubsub.publish(topic, data);
The cool part of this process is that with GraphQL subscriptions you have to have an async iterator to get published messages on UI, otherwise it is the same as having a basic Query type.
As you can imagine each PubSub topic as a Queue which operates in a “First In, First Out” concept, and it’s actually shared across all customers. At first, we’ve been making new PubSub object for every subscription, BUT it ended up taking a lot of resources because each topic allocates specific memory size and it frees up ONLY when you manually handling connection close and cleaning up that specific topic queue.
We basically wrapped default PubSub class and now, whenever Websocket connection closes, and async iterator stops iterating, it destroys itself automatically. And the cool part is that we now making single PubSub objects across the entire service, but for each customer, we are making a separate topic, which allowed us to pass global pubsub objects across multiple modules and send objects to UI without even having that functionality for the specific module.
1M WebSocket issue
If you can imagine what it means to actually have 1M live WebSocket connections, you will get an idea that it just requires a lot of resources, which is quite hard to scale automatically, even tho we have all our infrastructure on Google Cloud Kubernetes.
Core concepts of Live TCP connection are that it requires
open file/socket
allocated memory for IO buffers
CPU cycles to manage data flow events
all of the points are super limited by OS itself. Of course, it depends on your application performance as well, but if you have everything as we did (basic, default way), then your main limitations or performance issues are actually coming from these 3 limitations.
For example, if you will spin up Apache Server as the main Websocket handler instead of Nginx, you will probably get a huge headache, because Apache is not async and will take up a lot of resources to keep the single connection alive. So choosing Load Balancing software is crucial, and you actually can’t go without having a Load Balancer, because in any case, you will want to scale your API instance from one to multiple, that’s just the nature of having microservices.
Nginx actually is a lot cheaper in resource usage compared to other software load balancers, however, there is some specific tuning that we had to do in other to make it more reliable with WebSocket connections.
worker_processes auto;
events {
use epoll; # Using OS's base Event Loop for IO operations
worker_connections 1024;
multi_accept on;
}
....
location '/ws' {
......
proxy_http_version 1.1;
proxy_set_header Connection $connection_upgrade;
proxy_set_header Upgrade $http_upgrade;
proxy_read_timeout 999950s; # Just a large number to wait for data
}
....
The most important part here is to add use epoll configuration, which means that Nginx will maintain all connections over the base Linux Epoll event loop system managing entire IO for all hardware drivers. That 2 words actually dropped our CPU and Memory usage by 4-5 times, because after that Nginx wasn’t maintaining data buffering for specific sockets, that’s done by OS Epoll itself, which then transferred buffer and socket state to Nginx with a basic Event principle.
Why WebSockets is not so popular?
I think the reason that most of the companies still using basic HTTP requests were that they think it is hard to maintain. However, using GraphQL Subscriptions, it is completely abstracted away, and the developer actually doesn’t feel any difference, because it is the same GraphQL Types and same resolvers. The only difference is that developers should understand base concepts of having a PubSub system and that all messages/data flow passing over Queue principle (First In, First Out). It is actually possible to connect GraphQL Subscriptions PubSub to Redis or any other Queue (DB) system, but it just depends on the specific use-case.
We are continuing to move more and more stuff from basic Queries to Subscriptions to provide more interactive UI to our users, but I’ll agree that it is not going to replace standard Request Response entirely.
Help making more of this type of content, by sharing and clapping to this article 👏👏